

Все ли мы знаем про OOMKilled
Pod упал. Так часто говорят, подразумевая падение основного контейнера в поде, проще говоря нашего приложения в Openshift или Kubernetes. Падение основного контейнера влечет за собой его перезагрузку, а по-умолчанию и перезагрузку всего пода целиком. В этом случае мы залезаем в манифест пода, чтобы посмотреть причину падения, указанную в exitCode, и часто видим там код 137 именуемый OOMKilled
containerStatuses:
- name: logging-app
state:
running:
startedAt: '2024-12-07T11:49:19Z'
lastState: {}
ready: true
restartCount: 0
image: busybox:1.28
imageID: >-
docker-pullable://busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47
containerID: >-
docker://4aa632d8ec83829bebd24514596fb144a155d35a68ef5b6d9126b9f9c53ef2a4
started: true
- name: service-back
state:
running:
startedAt: '2024-12-07T11:52:10Z'
lastState:
terminated:
exitCode: 137
reason: Error
startedAt: '2024-12-07T11:49:17Z'
finishedAt: '2024-12-07T11:52:09Z'
containerID: >-
docker://290b76d274e031b6438f8edf27542f526960b19db7490bbf17340186f3e39294
ready: true
restartCount: 1
image: lokrusta/lokrusta-repo:service-back-0.01-SNAPSHOT
imageID: >-
docker-pullable://lokrusta/lokrusta-repo@sha256:c01e63adf2e3d6e39e9407bab0a43fc2d33f187c59b1bf69c17870a0e06352fa
containerID: >-
docker://8abe45e151bdae129a39a3ae579a5c8a35dd70867bcde47129484a908e5772d1
started: true
Документация по этой ошибке говорит о том, что ее причина в недостатке памяти для пода или одного из его контейнеров. И если у нас в контейнере java приложение, то первое (а бывает и единственное), что приходит на ум, это переполнение java heap или других областей памяти, относящейся к java (стек, metaspace, память для скомпилированных методов итд). В реальности причины 137 ошибки могут лежать за пределами кучи или Java памяти, а могут быть даже вообще не связаны с нехваткой ресурсов.
В данной статье мы рассмотрим несколько примеров, когда возникает OOMKilled, порядок разбора таких ситуаций и подводные камни, с которым можем столкнуться на этом пути.
Эксперименты будем проводить на тестовом микросервисе service-back-0.01, который предоставляет REST API для поиска сотрудников компании по начальным буквам их фамилий или табельным номерам. Нагрузка на сервис будет подаваться с помощью утилиты k6 (она подробно разбирается в других статьях).
Рассмотрим, как в манифесте Deployment указаны ресурсы для контейнера service-back:
env:
- name: JAVA_TOOL_OPTIONS
value: "-Xms256m -Xmx512m"
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 1000m
memory: 1Gi
Мы выделили на весь сервис 1 гигабайт памяти, а на Java-приложение в основном контейнере максимум 512 мегабайт, оставив еще столько же на нужды операционной системы. При этом limits указали равным requests, таким образом исключив, что мы получим 137 ошибку из-за того, что наш под запросит дополнительной памяти, которой уже нет в кластере Kuberneres. Фактически, наш подход означает, что мы протестировали под нагрузкой наш сервис и знаем, что всего ему должно хватать 1 гигабайт памяти, а самому Java приложению достаточно 512 мегабайт. Таким образом, если сервису не хватит памяти, то мы ожидаем увидеть java.lang.OutOfMemory в логах, а других причин упасть с OOMKilled на первый взгляд нет. Что ж давайте это проверим.
Эмулируем переполнение кучи
Чтобы сэмулировать переполнение кучи, добавим в обработчик запроcов к сервису следующий код:
private static final int MAX_ARRAY_SIZE = 70000;
@Override
@SneakyThrows
public List<EmployeeInfo> getEmployee(FindParams findParams) {
for (long i = 0; i < MAX_ARRAY_SIZE; i++) {
longList.add(i);
}
...
То есть, при каждом вызове service-back мы резервируем в куче 70 тысяч экземпляров типа Long, а это получается
70000* 8 байт = 560000 байт или 547 килобайт
Получается, при размере всей java памяти в 512 мегабайт, мы должны ее всю израсходовать примерно за 960 вызовов. Это хорошо, потому что тогда на графиках мы нагляднее увидим постепенный рост. Мы настроили эмулятор нагрузки k6 примерно на 3000 запросов в минуту, соответственно, примерно через 20 секунд в логе пода мы видим:
java.lang.OutOfMemoryError: Java heap space
У нас также обязательно должны присутствовать дашборды мониторинга ресурсов нашего сервиса, которые должны будут подтвердить постоянный рост памяти Java (мы специально говорим о всей памяти, а не только размере кучи):

Разрывы между двумя участками дашборда, как раз, будут свидетельствовать о том, что в этот момент под перезагружался, а ровная, практически не растущая вверх, кривая на втором участке показывает, что повторно нагрузка на под не подавалась.
Для мониторинга Java memory space мы можем просуммировать стандартную метрику jvm_memory_used_bytes в разрезе всех или конкретных видов памяти, а также с уточнением сервиса и пода:
sum(jvm_memory_used_bytes{service="$service", pod=~"$pod", id=~"$id"})
Что же дальше? Если по коду мы сервиса мы не можем предположить (или подтвердить гипотезу), что именно приводит к утечке памяти, нам на помощь приходят стандартные возможности Java, позволяющие снять дамп памяти при возникновении OutOfMemoryError. Для этого в настройки запуска нашего сервиса в манифесте Deployment добавим:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/path/dump.bin
Первым параметром мы включаем снятие дампа памяти, а во второй настройке указываем путь к файлу, в котором его надо разметить. Обратите внимание, что мы указали путь к временной папке пода (opt/app), указанной как workingDir — ниже мы рассмотрим правильность и последствия такого решения.
spec:
containers:
- name: service-back
image: "lokrusta/lokrusta-repo:service-back-0.01-SNAPSHOT"
workingDir: /opt/app
env:
- name: JAVA_TOOL_OPTIONS
value: "-Xms256m -Xmx512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/app/dump.bin"
После внесения изменений снова запускаем нагрузку, повторно по логу и графикам убеждаемся в том, что причина падения пода OutOfMemory и пытаемся скачать дамп памяти.
Это можно сделать следующей командой Kubernetes:
kubectl -n myproject cp service-back-0.01-798f5fc6c6-2ddt5:/opt/app/dump.bin /Work/dump.bin
В настройках команды cp мы укажем имя пода, папки на поде и имя локальной папки для скачивания дампа.
Запустив данную команду мы почти наверняка столкнемся с одной из проблем:
1) Мы пытаемся скачать дамп пока он еще формируется java машиной и файл получится битым, о чем мы получим соответствующее сообщение
2) В процессе скачивания дампа мы получим сообщение, что контейнер в статусе OOMKilled и продолжение работы невозможно
3) Команда не обнаружит файла, так как на момент ее запуска pod будет перезагружен и временные тома смонтированы заново
Отсюда вывод — дамп надо размещать на самой ноде через hostPath или персистентном хранилище. Для простоты выберем первый вариант добавив следующее монтирование в deployment:
volumeMounts:
- name: dump-volume
mountPath: /dump
volumes:
- name: dump-volume
hostPath:
path: /var/tmp
type: Directory
Если тестирование происходит на локальной машине с использованием minikube и Oracle Virtual Box (про настройку minikube можно прочитать в отдельной статье), то, чтобы понять какие папки есть на виртуальной машине хоста, нужно зайти на хост minikube через Oracle Virtual Box (дефолтные имя и пароль — docer/tcuser) и посмотреть их структуру командой ls. Папка var/tmp – стандартная, в нее мы и будем записывать дамп памяти
Меняем в деплойменте путь к дампу на:
-XX:HeapDumpPath=/dump/dump.bin
и повторяем эксперимент
Далее, после того как на дашборде увидим, что под повторно ушел в перезагрузку, повторяем попытку скачать дамп. (Раньше того как произойдет перезагрузка пода дамп скачать вряд ли получится из-за ошибки 137):
kubectl -n myproject cp service-back-0.01-798f5fc6c6-2ddt5:/dump/dump.bin /Work/dump.bin
Defaulted container "service-back" out of: service-back, logging-app
tar: Removing leading `/' from member names
После получения дампа на локальную машину мы можем проанализировать его с помощью Eclipce Memory Analizer (сокращенно mat). Перед запуском исполняемого файла рекомендуется увеличить максимальный размер памяти в MemoryAnalizer.ini, чтобы дамп гарантированно поместился:
-Xmx4096m
В нашем примере после открытия дампа данной утилитой, мы в качестве главной причины утечки увидим создаваемый нами массив чисел Long:
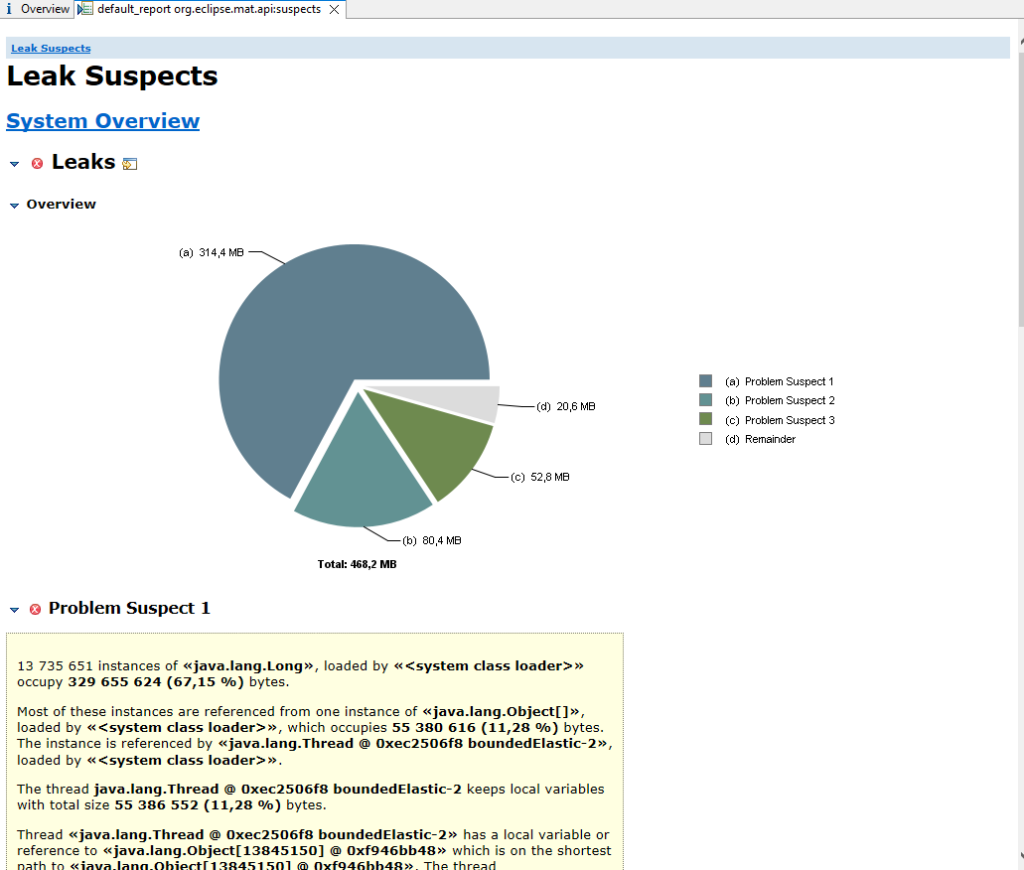
Теперь только остается поправить код и убедиться, что проблема решена!
Нехватка памяти за пределами Java-машины
В приведенном выше примере нам облегчало задачу то, что мы видели ошибку OutOfMemory в логе пода и получали дамп памяти, но, что если Java приложение не подает никаких признаков проблемной работы, а под периодически перезагружается с ошибкой 137? Может ли такое быть? Конечно, да! Например, если мы укажем только значение requests, а на ноде не окажется свободной памяти или максимальный объем памяти Java сделаем таким, чтобы он мог забрать всю доступную память на поде:
env:
- name: JAVA_TOOL_OPTIONS
value: "-Xms256m -Xmx1024m"
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 1000m
memory: 1Gi
В этом случае в с точки зрения Java проблем у нас быть не должно — расходуя кучу в рамках допустимых границ мы ничего не нарушим, но сам контейнер убьем. Но, тогда на графике Java Memory Heap мы увидим соответствующую картину. А если объем используемой Java памяти не растет на графиках, но под тем не менее падает? В чем еще может быть проблема?
Давайте еще раз вспомним, что память контейнера с java приложением можно разделить на 2 вида — это память java и память операционки и проблемы могут быть с любой из них. Возникает вопрос, отчего может переполниться память операционки, если в ней кроме java-приложения все относительно статично? Дело в том, что как известно, java может использовать память вне кучи — так называемые Direct Buffers. Причем разработчики могут даже догадываться о том, что приложение активно использует прямые буфера. Это может делать неявно какой-то из компонентов приложения, например, сервер netty.
По-умолчанию, под прямые буфера доступен тот же объем памяти, что и максимальный размер памяти java, указанный через —Xmx. То есть, если для java мы зарезервировали 512 мегабайт, то еще столько же будет по-умолчанию доступно для прямых буферов в операционке. Изменить этот параметр мы можем настройкой:
-XX:MaxDirectMemorySize
И это бывает очень полезно сделать, чтобы при попытке резервирования большего объема памяти за пределами кучи мы получили более понятную OutOfMemory, а не просто перезагрузку пода. Но, конечно, это не решит проблемы, если мы не состыкуем настройку -XX:MaxDirectMemorySize с API, которое использует память вне кучи.
Для нашего нового эксперимента мы укажем следующие настройки запуска приложения в Deployment:
env:
- name: JAVA_TOOL_OPTIONS
value: "-Xms256m -Xmx1024m"
А в коде при выполнении очередного запроса добавим резервирование 150000 байт памяти за пределами кучи.
private static final int MAX_ALLOCATE_SIZE = 150000;
@Override
@SneakyThrows
public List<EmployeeInfo> getEmployee(FindParams findParams) {
buffers.add(ByteBuffer.allocateDirect(MAX_ALLOCATE_SIZE));
...
Таким образом, если за пределами кучи нам доступено 768 мегабайт (так как остальные 256 занимает память java), то нам потребуется около 5500 запросов чтобы съесть всю память. Но, часть памяти вне кучи уже используется операционкой, поэтому выполнив за минуту около 3000 запросов мы уже получим перезагрузку пода
Ниже представлен график памяти, который был затрачен под прямые буфера во время эксперимента и после перезагрузки пода, когда нагрузка уже не подавалась:

Как мы видели уже ранее, разрыв между кривыми на дашборде свидетельствует о факте перезагрузки пода. Также видно, что мы успели зарезервировать около 700 мегабайт под прямые буфера до того как получили OOMKilled. Это примерно соответствует нашим ожиданиям — 256 минимум на Java, 700 на direct memory и оставшиеся 50 на остальные процессы операционки.
Для примера ниже представлен график использования Direct Memory, который был при нашем первом эксперименте с переполнением Java памяти. Как ни странно, память прямых буферов тоже росла при резервировании памяти в куче, но незначительно и на ход эксперимента влияния не оказала

Информацию о размере памяти, занимаемой прямыми буферами можно получить запросом стандартной метрики jvm_buffer_memory_used_bytes и указав в качестве тэга id значение ditect:
sum(jvm_buffer_memory_used_bytes{service="$service", pod=~"$pod", id=~"$id"})
Итак, во втором нашем эксперименте мы увидели почему может возникнуть OOMKilled без соответствующего возникновения OutOfMemory в java и как это диагностировать. Чтобы избежать переполнения прямых буферов можно использовать настройку XX:MaxDirectMemorySize на уровне Java или тюнинговать API, которое использует прямые буфера. В случае с API Reator Netty можно указать следующие настройки для избежания их использования:
-Dio.netty.allocator.numDirectArenas=0, -Dio.netty.noPreferDirect=true
Ошибки SSL, маскирующиеся под OutOfMemory
Ну, и напоследок приведем пример еще одного случая, когда в логах пода мы будем получать OutOfMemory с последующей за ней OOMKilled, хотя к переполнению памяти данный кейс не будет иметь никакого отношения. Случай довольно экзотический, но не сказать, чтоб слишком редкий, если ваше java приложение работает с Кафкой.
Работе с Кафкой на сайте будет посвящено несколько статей, а сейчас достаточно сказать, что есть несколько вариантов подключения к серверам брокеров Кафки, в том числе небезопасное подключение через протокол PLAINTEXT и безопасное по протоколу SSL.
Для подключения по SSL предусмотрен ряд стандартных настроек, которые можно вынести в конфигмапу, а затем из конфигмапы передать в код инициализации Кафка конзюмера или продюсера или в код спринговых DefaultKafkaProducerFactory и DefaultKafkaConsumerFactory. В число таких настроек входят:
security.protocol
ssl.truststore.location
ssl.keystore.location
ssl.key.password
ssl.keystore.password
ssl.truststore.password
ssl.endpoint.identification.algorithm
Если по ошибке, мы укажем в качестве security.protocol значение SSL, но, например, вообще, не заполним другие ssl-настройки, то в логах увидим примерно следующее:
java.lang.OutOfMemoryError: Java heap space
at java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:57)
at java.nio.ByteBuffer.allocate(ByteBuffer.java:335)
at org.apache.kafka.common.network.NetworkReceive.readFromReadableChannel(NetworkReceive.java:93)
at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:71)
at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:153)
at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:134)
at org.apache.kafka.common.network.Selector.poll(Selector.java:286)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:256)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:216)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:128)
at java.lang.Thread.run(Thread.java:745)
Таким способом Кафка маскирует реальную ошибку SSL handshake failed, чтобы ввести в заблуждение потенциальных злоумышленников. Однако незнание данного факта может сильно ввести в заблуждение также и разработчика, которых в настроечных скриптах конфигмапы (а ее содержимое в реальных проектах генерируется на основании настроек в репозиториях, применяемых к разным стендам шаблонизаторами типа jinja2) допустят ошибку.
