

Мониторинг кластера Kubernetes
Источники метрик в кластере Kubernetes
В первой статье мы рассмотрели как установить стек мониторинга в кластер Kubernetes и настроить мониторинг прикладных сервисов. Наш дашборд использовал специфичные метрики определенного сервиса и, хотя набор прикладных метрик для сервисов можно унифицировать, программирование прикладных метрик — задача разработчика. В противовес прикладным метрикам существует большое количество системных метрик, которые отбрасываются различными службами и системными библиотеками Spring. В приведенной ниже таблице указаны различные источники системных метрик и их особенности:
|
Источник |
Как метрики попадают в Prometheus |
Примеры метрик |
Использование |
Значение тэга Job |
|
Системные библиотеки прикладных приложений (Spring. Webflux и др) |
Нужно настроить мониторинг, конкретного прикладного сервиса, например, через манифест ServiceMonitor |
jvm_memory_used_bytes process_cpu_usage |
Для контейнеров, работающих на Java, с помощью системных метрик, отбрасываемых библиотекой Spring, можно сформировать дашборды использования ресурсов — память, процессор, direct buffers, garbage collector, class loading |
Отсутствует |
|
Metrics-server (kubelet) |
Автоматически, если установлен metrics-server и kube-prometheus-stack |
container_cpu_usage_seconds_total container_memory_working_set_bytes container_start_time_seconds pod_cpu_usage_seconds_total pod_memory_working_set_bytes |
На этих метриках можно сформировать дашборд по утилизации памяти и CPU подами и контейнерами. Используются для автоматического масштабирования с помощью Horizontal Pod Autoscaler и Vertical Pod Autoscaler |
kubelet |
|
node-exporter |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с node_: node_cpu_seconds_total node_disk_info |
Получение различной информации о ресурсах ноды, связанных с оборудованием и ядром |
node-exporter |
|
kube-state-metrics |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с kube_: kube_node_info kube_configmap_info |
Получение информации о состоянии объектов API (deployments, pods, statefulsets итд) путем перехвата обращений к API-серверу Kubernetes |
kube-state-metrics |
|
Различные системные службы — Grafana |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с grafana_ |
Метрики Grafana |
grafana |
|
Различные системные службы — Prometheus |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с prometheus_ |
Метрики Prometheus |
prometheus-k8s |
|
Различные системные службы — AletrManager |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с alertmanager_ |
Метрики AlertManager |
alertmanager-main |
|
Различные системные службы — Планировщик |
Автоматически, если установлен kube-prometheus-stack |
Метрики планировщика |
kube-scheduler |
|
|
Различные системные службы — Менеджер контроллеров |
Автоматически, если установлен kube-prometheus-stack |
Метрики менеджера контроллеров |
kube-controller-manager |
|
|
Различные системные службы — Kubelet |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с kubelet_ |
Метрики Kubelet |
kubelet |
|
Различные системные службы — ApiServer |
Автоматически, если установлен kube-prometheus-stack |
Названия метрик начинаются с apiserver_ |
Метрики ApiServer |
apiserver |
Архитектура metrics-server
Рассмотрим базовые метрики ресурсов, получаемые с помощью metrics-server. Архитектура metrics-server представлена на рисунке 1
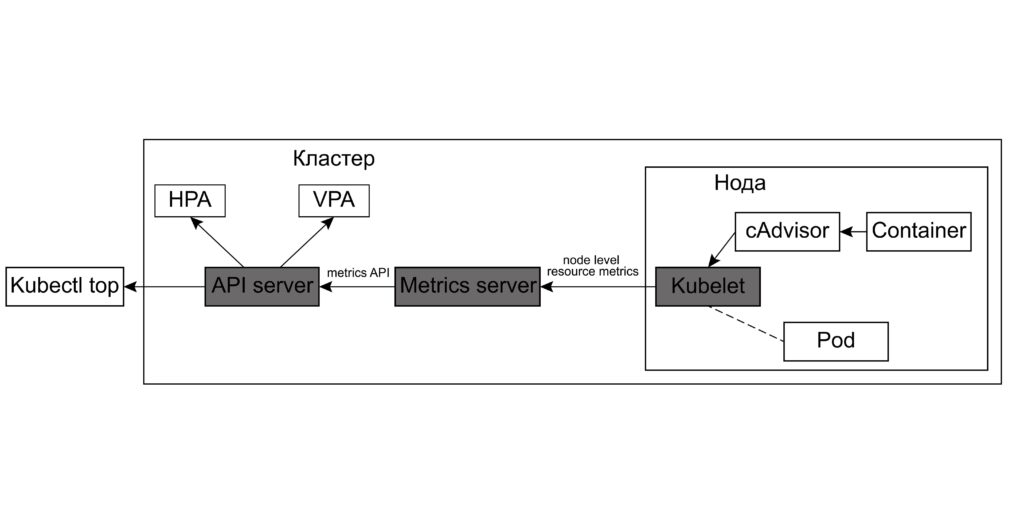
Kubelet, работающий на каждой ноде, собирает с нее метрики. В дополнение к этому, можно установить приложение cAdvisor в качестве DaemonSet (описание установки cAdvisor можно найти тут — https://github.com/google/cadvisor/tree/master/deploy/kubernetes). Тогда в kubelet дополнительно будут попадать метрики контейнеров, собираемые с помощью cAdvisor). Далее, metrics-server собирает метрики со всех kubelets на кластере, а API server предоставляет доступ к этим метрикам. Kubernetes получает данные о ресурсах подов и ноды для управления масштабированием deployment-ов, с помощью объектов Horizontal Pod Autoscaler и Vertical Pod Autoscaler, а также для утилиты kubectl top:
C:\Windows\System32>kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
minikube 236m 3% 3095Mi 52%
Команда kubectl top pod без параметров выдаст информацию о ресурсах подов дефолтного нэймспейса. Сменить нэймспейс по-умолчанию можно командой:
kubectl config set-context --current --namespace myproject
Если дополнительно указать имя конкретного пода, то будут выданы данные именно по нему:
C:\Windows\System32>kubectl top pod service-back-0.01-6cd5c67f6d-cznlz
NAME CPU(cores) MEMORY(bytes)
service-back-0.01-6cd5c67f6d-cznlz 4m 201Mi
Обратите внимание, что для всей ноды в целом информация выдается как в абсолютных значениях так и в % от доступных значений, в то время как для каждого пода выдаются абсолютные данные. Интересно, что в нашем примере кластеру Kubernetes доступно 6 процессоров или 6000m, в то время как используемые 236m, это примерно 4%, общий объем памяти кластера 6G, а 3095Mi (3169M) это примерно 52.8%. Также уточним про единицы измерения — 4m это 4 миликора, т.е. 0.004% процессора, а 201Mi это 201 * 1024K, т.е примерно 206M.
Получить все доступные через metrics API метрики можно командой:
kubectl get --raw /api/v1/nodes/minikube/proxy/metrics/resource
Выполнив в выдаче данной команды поиск по имени нэймспейса myproject, в котором мы разместили тестовый микросервис, мы увидим следующий набор метрик:
container_cpu_usage_seconds_total{container="service-back",namespace="myproject",pod="service-back-0.01-6cd5c67f6d-cznlz"}
container_memory_working_set_bytes{container="service-back",namespace="myproject",pod="service-back-0.01-6cd5c67f6d-cznlz"}
container_start_time_seconds{container="service-back",namespace="myproject",pod="service-back-0.01-6cd5c67f6d-cznlz"}
pod_cpu_usage_seconds_total{namespace="myproject",pod="service-back-0.01-6cd5c67f6d-cznlz"}
pod_memory_working_set_bytes{namespace="myproject",pod="service-back-0.01-6cd5c67f6d-cznlz"}
В него входит использование памяти и процессора контейнером и подом нашего микросервиса и время старта контейнера.
Давайте теперь прокинем порт Prometheus:
kubectl port-forward pods/prometheus-k8s-0 9090:9090 -n monitoring
и поищем те же метрики в нем, зайдя в его Web-интерфейс по адресу http://localhost:9090. Например, поиском по имени метрики и тэгу namespace мы найдем метрики по контейнеру, но с другим набором тэгов, в частности, с тегом pod. Метрик pod_cpu_usage_seconds_total и pod_memory_working_set_bytes мы не обнаружим, но мы можем получить нужные нам значения просуммировав метрики по контейнерам с агрегацией по подам.
container_cpu_usage_seconds_total{cpu="total", endpoint="https-metrics", id="/kubepods/pod1a2ec331-5439-4690-862a-0509182ba8a9", instance="172.27.231.8:10250", job="kubelet", metrics_path="/metrics/cadvisor", namespace="myproject", node="minikube", pod="service-back-0.01-6cd5c67f6d-cznlz", service="kubelet"}
container_memory_working_set_bytes{endpoint="https-metrics", id="/kubepods/pod1a2ec331-5439-4690-862a-0509182ba8a9", instance="172.27.231.8:10250", job="kubelet", metrics_path="/metrics/cadvisor", namespace="myproject", node="minikube", pod="service-back-0.01-6cd5c67f6d-cznlz", service="kubelet"}
container_start_time_seconds{endpoint="https-metrics", id="/kubepods/pod1a2ec331-5439-4690-862a-0509182ba8a9", instance="172.27.231.8:10250", job="kubelet", metrics_path="/metrics/cadvisor", namespace="myproject", node="minikube", pod="service-back-0.01-6cd5c67f6d-cznlz", service="kubelet"}
Управление автомасштабированием развертываний c использованием Horizontal Pod Autoscaler
Как мы говорили выше, метрики подов, доступные через metrics-server позволяют управлять количеством подов развертывания, задавая условия по максимальному значению утилизации памяти или процессора при котором будут создаваться новые поды. Для настройки горизонтального автомасштабирования используется манифест типа HorizontalPodAutoscaler:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: service-back-0.01-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: service-back-0.01
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 500Mi
В нашем примере указано, что микросервис service-back-0.01 может масштабироваться максимально до 3-х подов при условии превышения 70% утилизации процессора и 500Mi памяти используемых одним подом. Для тестирования мы можем в каждом из показателей задать заведомо маленькие значения (например, 1% процессора и 50Mi памяти), чтобы увидеть, что количество подов увеличилось до 3-х.
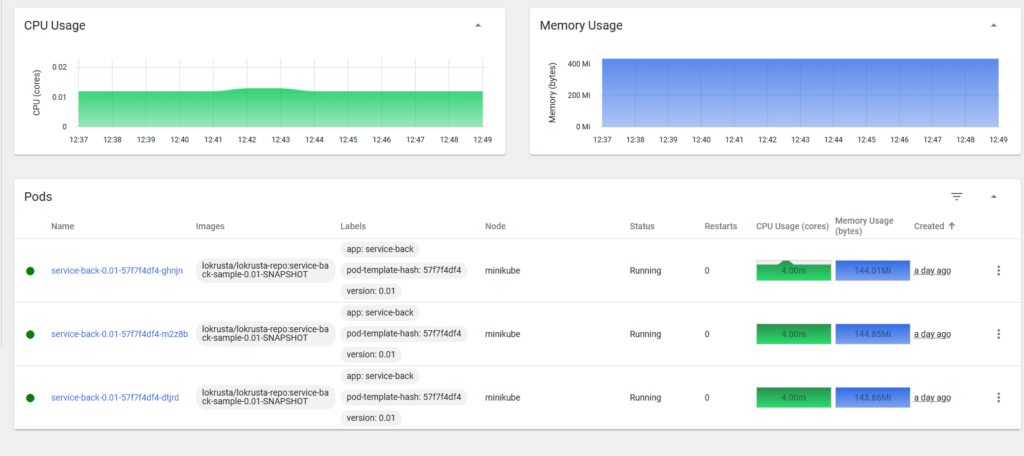
C:\Windows\System32>kubectl top pod
NAME CPU(cores) MEMORY(bytes)
service-back-0.01-57f7f4df4-dtjrd 4m 131Mi
service-back-0.01-57f7f4df4-ghnjn 9m 128Mi
service-back-0.01-57f7f4df4-m2z8b 8m 125Mi
После возврата в настройках HorizontalPodAutoscaler нормальных значений для памяти и CPU количество экземпляров service-back-0.01 смасштабируется до одного.
В HorizontalPodAutoscaler можно также закладываться на пользовательские метрики, но рассмотрение данного механизма выходит за рамки этой статьи. Также Kubernetes предоставляет возможность вертикального масштабирования путем добавления ресурсов к существующему поду, а не новых подов. За это отвечает манифест VerticalPodAutoscaler, который чаще применяется к сервисам размещаемым как statefulsets, а не deployments, например, базам данных. Это понятно, так как StatefulSet-ы сложно масштабировать горизонтально из-за уникальности каждой реплики.
Дашборды для мониторинга кластера, поставляемые kube-prometheus-stack
Grafana, устанавливаемая в составе kube-prometheus-stack, содержит набор дашбордов, отслеживающих состояние кластера. Каждый дашборд поставляется внутри ConfigMap в пространстве monitoring и монтируется во временную файловую систему. Поэтому, надо учитывать, что все изменения, внесенные в дашборды пропадут, если под Grafan-ы будет удален. Чтобы этого избежать, можно перенастроить конфигурацию развертывания Grafan-ы и размещать файлы дашбордов на томах типа nodePath или через Persistent Volume Claims.
Дашборды Grafana поставляемой в составе kube-prometheus содержат следующую информацию:
Дашборды стандартных служб:
Api Server
Kubelet
KubeProxy
Scheduler
Controller Manager
Grafana
AlertManager
Prometheus
Эта группа дашбордов отображает метрики специфичные для конкретной службы, а также использование памяти и CPU службой
Например, дашборд Kubernetes->Scheduler отображает:
- 99-перцентиль latency Get и POST запросов
- 99-перцентиль времени операций планировщика
- частота операций планировщика(операций в секунду)
- использование памяти, CPU
Дашборд Kubernetes->Kubelet:
- сколько всего запущено экземпляров Kubelet, подов, контейнеров
- частота выполнения операций различного типа (операций в секунду)
- 99-перцентиль по операциям различного типа
- использование памяти, CPU
Дашборды ресурсов в разрезе:
Кластера
Нэймспейса
Пода
Ноды
Рабочей нагрузки (Worload)
Например, дашборд Kubernetes→ Compute Resources→ Workload показывает
- Использование CPU и Памяти соответствующим объектом (например, deployment-ом)
- Использование сети (количество полученных байт)
- Сетевая пропускная способность — общая и средняя в разрезе пода
Дашборды сетевой активности в разрезе:
Кластера
Нэймспейса
Пода
Ноды
Workload-а
Эта группа дашбордов показывает:
- скорость получения/отправки (байт в секунду)
- пропускную способность
- ошибки передачи
Дашборд с информацией о Persistent Volumes
Прочие дашборды
Чтобы посмотреть дашборды, нужно прокинуть порт Grafan-ы:
kubectl --namespace monitoring port-forward svc/grafana 3000
Далее зайти на http://localhost:3000 и ввести имя и пароль по-умолчанию — admin/admin
Теперь заходим в пункт меню Dashboards и открываем папку Default
Откроем дашборд ресурсов кластера Kubernetes→Compute Resources → Cluster. На нем мы видим в верхней панели утилизацию CPU, запрошенный размер CPU в % от доступного, общий лимит CPU в % от доступного, утилизацию памяти, запрошенный размер памяти в % от доступного, общий лимит памяти в % от доступного.
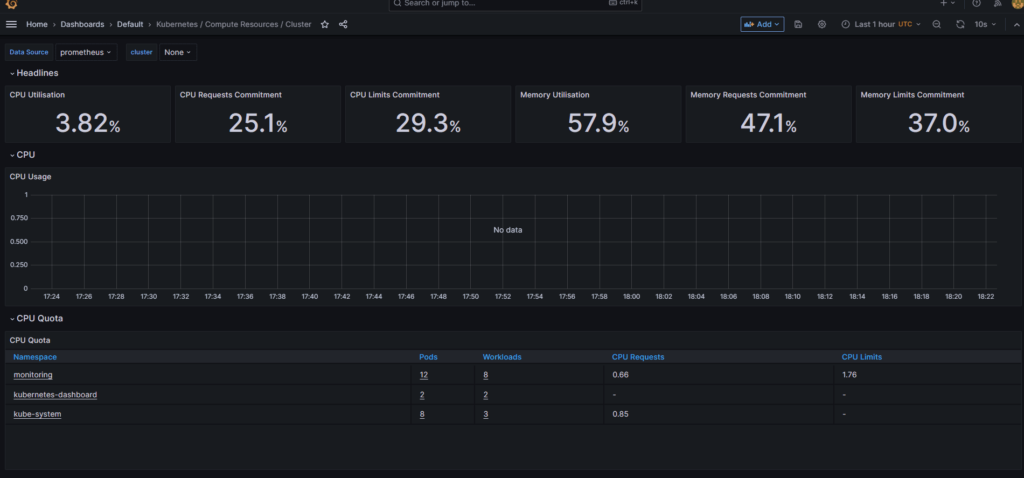
Теперь кликнем в правом верхнем углу прямоугольника CPU Utilization и выберем в выпадающем меню пункт Edit
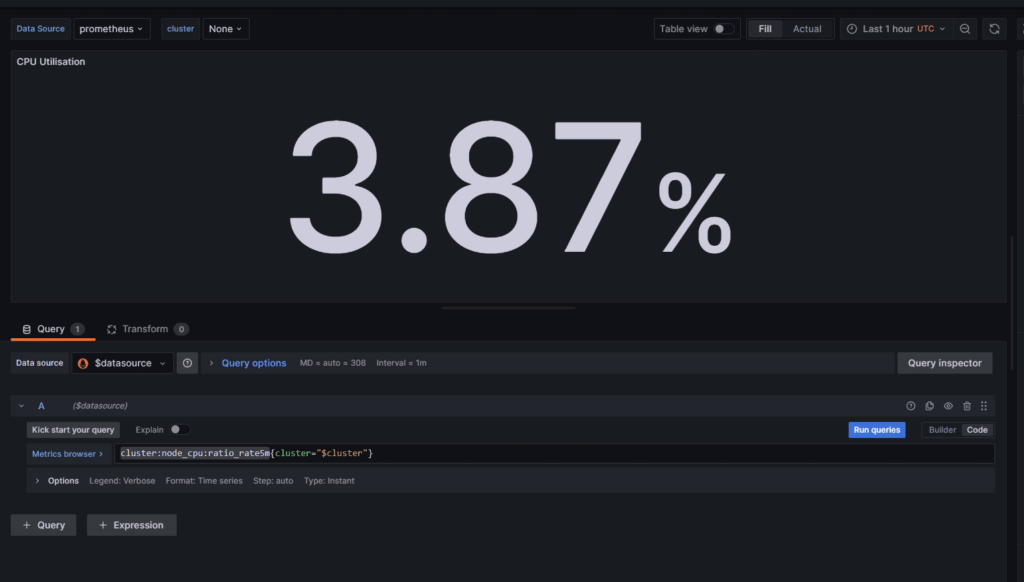
В нижней части мы увидим выражение, на основе которого вычисляется метрика:
cluster:node_cpu:ratio_rate5m
Это выражение является правилом, настроенным в Prometheus, то есть формулой основанной на других формулах или метриках и встроенных функциях. Правила Prometheus, как и дашборды Grafana, хранятся в ConfigMaps и монтируются во временную файловую систему пода.
ConfigMap для правил Prometheus, поставляемый в составе kube-prometheus-stack, называется prometheus-k8s-rulefiles-0. Открыв его и поискав выражение cluster:node_cpu:ratio_rate5m мы увидим:
- expr: |
avg by (cluster) (
node:node_cpu_utilization:ratio_rate5m
)
record: cluster:node_cpu:ratio_rate5m
То есть это среднее по кластеру значение другого выражения:
- expr: |
avg by (cluster, node) (
sum without (mode) (
rate(node_cpu_seconds_total{mode!=\"idle\",mode!=\"iowait\",mode!=\"steal\",job=\"node-exporter\"}[5m])
)
)
record: node:node_cpu_utilization:ratio_rate5m
А оно, в свою очередь, использует счетчик node_cpu_seconds, поставляемый утилитой node-exporter. Формула берет среднюю за 5-минутный интервал скорость изменения утилизации CPU нодами кластера.
Если посмотреть выражения на других дашбордах, то мы увидим, что большинство из них ссылаются на правила агрегации метрик в различных разрезах, настроенные в Prometheus.
Больше практической информации по настройке мониторинга вы можете получить на нашем бесплатном курсе.
