

Установка и настройка стека мониторинга в Kubernetes
Что такое мониторинг
Мониторинг — это один из компонентов наблюдаемости (observability) наряду с логированием и трассировкой. Наблюдаемость обеспечивает возможность получать информацию о работе приложения в различных разрезах, а мониторинг предоставляет информацию о ключевых показателях его работы (используемые ресурсы, производительность, различного рода статистика). Ключевые показатели именуются метриками, а совокупность компонентов обеспечивающих организацию мониторинга — стеком мониторинга.
Что входит в стек мониторинга
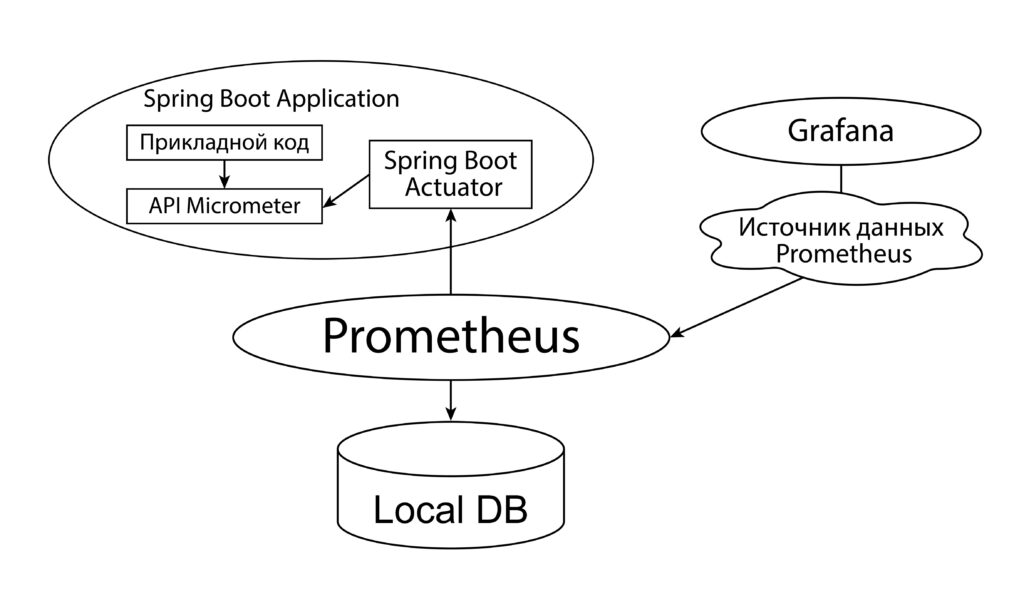
API, с помощью которого фиксируются метрики. Для приложений, написанных на Java и Spring в этом качестве принято использовать библиотеку Micrometer. О том как она работает и как использовать ее API можно прочитать здесь и здесь.
Системы сбора, хранения, агрегирования метрик. В качестве такой системы мы будем использовать Prometheus.
Системы визуализации метрик в виде различного рода графиков. Наиболее популярный вариант — это Grafana.
В мониторинге нуждаются не только прикладные приложения, но и сам кластер и его компоненты. Для этих целей в стеке мониторинга должна присутствовать система сбора информации о метриках различных объектов кластера. Выделим наиболее популярные варианты:
metrics-server — собирает метрики ресурсов пода из Kubelets и предоставляет их в Kubernetes apiserver через Metrics API для использования Horizontal Pod Autoscaler и Vertical Pod Autoscaler. Autoscaler-ы позволяют вертикально (увеличивая ресурсы) и горизонтально (увеличивая количество подов) масштабировать контейнеры. Собственно, масштабирование — единственная функция, для которой используется metric-server
kube-state-metrics работает по другому принципу. Перехватывая API Kubernetes, он формирует метрики о состоянии объектов кластера.
cAdvisor (Container Advisor) собирает информацию о работе контейнеров, которую предоставляет в виде метрик в Kubelet
node-exporter – еще одна утилита для получения различной информации о ресурсах ноды, связанных с оборудованием и ядром
В стеке мониторинга могут также присутствовать дополнительные компоненты, которые функционируют не сами по себе, а являются дополнением к другому компоненту стека мониторинга. Например, в дополнение к Prometheus могут использоваться:
alert-manager – компонент, обеспечивающий информирование о выходе значений метрик за пределы определенного диапазона
prometheus-adapter — компонент, позволяющий добавлять кастомные метрики контейнеров в Metrics API для дальнейшего их использования в том числе в Horizontal Pod Autoscaler и Vertical Pod Autoscaler
blackbox-exporter — позволяет осуществлять проверку внешних конечных точек по протоколам HTTP, HTTPS, DNS, TCP, ICMP и gRPC
Ну, и наконец важнейшим компонентом стека мониторинга являются преднастроенные объекты, позволяющие обеспечить мониторинг «из коробки». В первую очередь, это CDR (Custom Resource Definitions), облегчающие настройку мониторинга конкретного контейнера. Во-вторых, это преднастроенные правила Prometheus и уже готовые дашборды с различной информацией о ресурсах и компонентах кластера.
Варианты установки стека мониторинга
1) Полностью ручной вариант, предполагающий, что манифесты для развертывания компонентов пишутся вручную. Впрочем, найти конфигурации для установки Prometheus и Grafana можно найти на многих ресурсах сети. Вручную также придется настраивать мониторинг конкретных контейнеров и компонентов кластера
2) Установка Prometheus addon и Grafana addon, как описано на сайте Istio
3) Установка Prometheus Operator. Этот способ позволяет установить Prometheus и Custom Resource Definitions, через которые можно управлять мониторингом отдельных контейнеров, а также настройками самого Prometheus. Полное описание объектов API можно посмотреть тут. Но, в составе Prometheus Operator нет Grafana
4) Установка kube-prometheus-stack. Он включает в себя:
- Prometheus
- Grafana
- Custom Resource Definitions для настройки мониторинга (то что входит в Prometheus Operator)
- kube-state-metrics
- alertmanager
- node-exporter
- Набор дашбордов для мониторинга кластера
Установка kube-prometheus-stack
1) Клонируем репозиторий https://github.com/prometheus-operator/kube-prometheus
2) Обновляемся на ветку main
3) По инструкции к данному проекту на GitHub выполняем:
kubectl apply --server-side --force-conflicts -f <Путь до репозитория>/kube-prometheus/manifests/setup
kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring
kubectl apply --server-side --force-conflicts -f <Путь до репозитория>/kube-prometheus/manifests
Первая команда создает namespace monitoring и накатывает нужные Custom Resource Definitions
Вторая команда ждет, пока все созданные объекты Api корректно создадутся
Третья команда создает конфиги, основанные в том числе на новых Custom Resource Definitions, в результате которых запускаются Prometheus и Grafana и настраивается мониторинг кластера
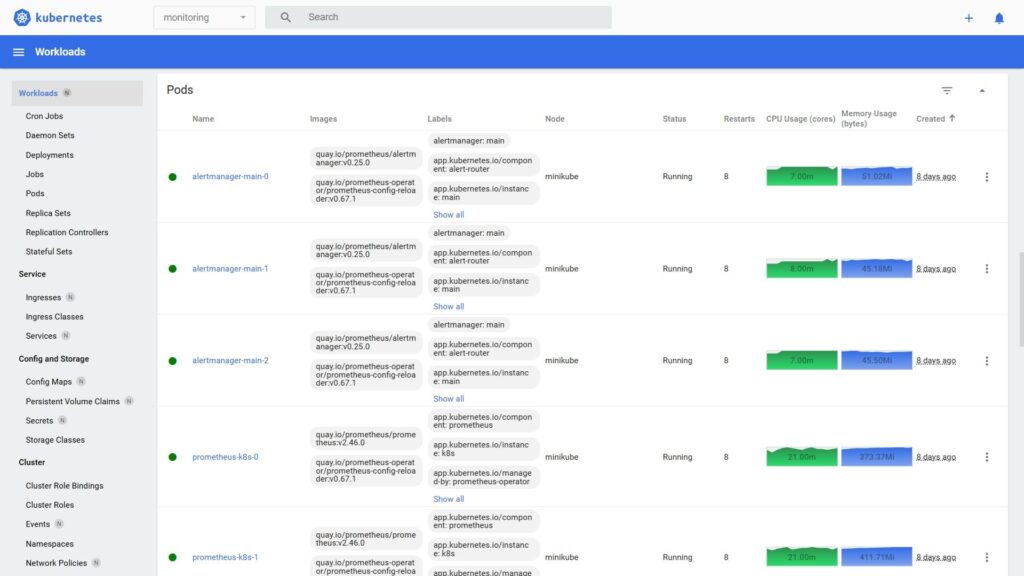
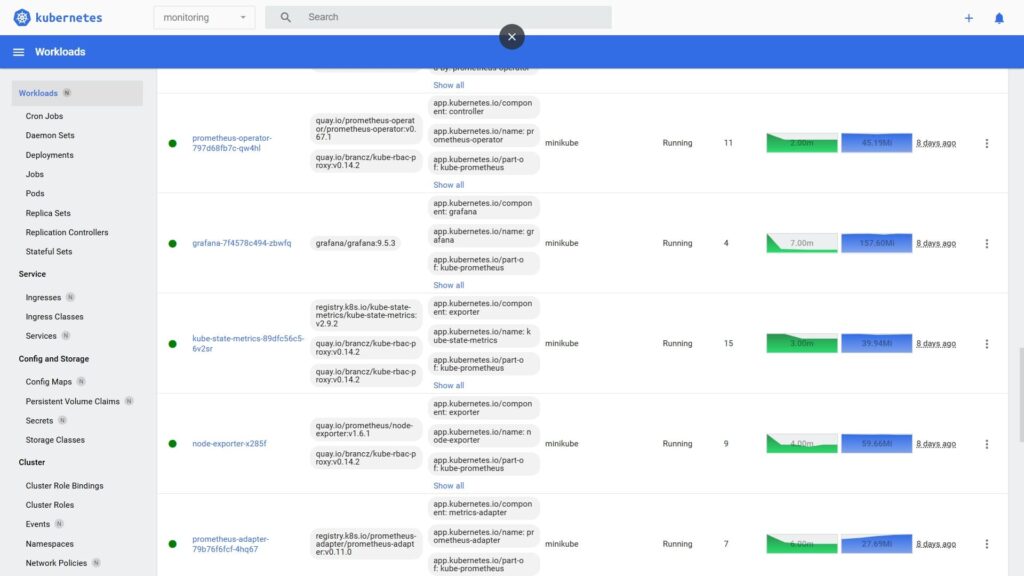
4) Проверка, что kube-prometheus нормально накатился
Открываем minikube dashboard и переходим в пространство имен monitoring.
Там должны увидеть:
- 2 пода statefulset prometheus-k8s
- Под Grafana
- 3 пода statefulset alertmanager
- Поды prometeus-operator, prometheus-adapter, node-exporter
- Под kube-state-metrics
5) Дополнительно рекомендуется включить metrics-server, который собирает с подов статистику ресурсов для обеспечения возможности автомасштабирования контейнеров:
minikube addons enable metrics-server
Проверить состояние metrics-server можно в пространстве kube-system:

Также для проверки метрик, поставляемых Metrics API через metrics-server, можно использовать команду kubectl top, которая выдает статистику ресурсов в разрезе всей ноды или подов:
C:\Windows\System32>kubectl top pod
NAME CPU(cores) MEMORY(bytes)
service-back-0.01-57f7f4df4-dtjrd 4m 131Mi
service-back-0.01-57f7f4df4-ghnjn 9m 128Mi
service-back-0.01-57f7f4df4-m2z8b 8m 125Mi
При ошибке команды kubectl top node сразу после включения metrics-server попробуйте перезагрузить кластер minikube (если вы используете его в качестве дистрибутива Kubernetes)
Более подробную информацию о мониторинге кластера Kubernetes вы можете прочитать в этой статье, а сейчас мы покажем как настроить мониторинг прикладных сервисов в кластере.
Настройка мониторинга прикладных сервисов
В первом уроке нашего бесплатного курса мы разработали микросервиc service-back-sample и разместили его пространстве myproject. В конфигурации Prometheus, которая настраивается через манифест Prometheus и лежит в файле prometheus-prometheus.yaml репозитория kube-prometheus есть следующие настройки:
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
Они разрешают Прометею мониторить все сервисы во всех пространствах имен. Но, чтобы мониторинг работал необходимо создать роль дающую доступ к объектам нужного нам нэймспейса myproject и привязать эту роль через RoleBinding к ServiceAccout-у Прометея:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: myproject
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: myproject
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
Также нам надо с помощью манифеста ServiceMonitor включить забор метрик Прометеусом из нашего микросервиса:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
serviceMonitor: prometheus
name: myproject-service-back-metrics
namespace: myproject
spec:
endpoints:
- interval: 5s
port: http-8081
scheme: http
path: /actuator/prometheus
selector:
matchLabels:
app: service-back
Обратите внимание, что мы указали порт 8081 и URL /actuator/prometheus, по которому доступен эндпоинт для метрик. Этот эндпоинт предоставляется через настройку Spring Boot Actuator и об этом можно прочитать в данной статье, а также во втором уроке нашего бесплатного курса.
Также мы указали интервал сбора метрик равный 5 секундам и в блоке selector задали метку микросервиса, к которому относятся данные настройки мониторинга.
После накта данных конфигураций через kubectl apply:
kubectl apply -f C:\Work\Projects\SampleOsApp\monitoring\prometheus-roles-myproject.yaml
kubectl apply -f C:\Work\Projects\SampleOsApp\monitoring\app_metrics.yaml
можно проверять работу мониторинга.
Просматриваем метрики Spring-приложения, обращаясь напрямую к микросервису и к Prometheus
На втором уроке нашего бесплатного курса, в код микросервиса service-back-sample был добавлен функционал отброса метрик и настроен Spring Boot Actuator для публикации метрик в Prometheus. В частности, наш микросервис отбрасывает метрику типа Counter с именем OPERATION_CODE и тэгами BUSINESS_PROCESS и CODE, которая фиксирует код завершения операции поиска сотрудников. Также отбрасывается Timer с именем OPERATION_TIME и тэгом BUSINESS_PROCESS, который фиксирует время операции поиска данных о сотрудниках. Подробнее о типах метрик Prometheus можно прочитать тут.
Для того, чтобы проверить метрики, откидываемые приложением мы подадим на него нагрузку, с помощью утилиты нагрузочного тестирования k6. Этот процесс также описан во втором уроке курса. После подачи нагрузки в течение 60 секунд можно обратиться напрямую к нашему микросервису и посмотреть какие метрики он выдает. Для этого можно было бы выполнить curl непосредственно из консоли микросервиса, но в нашем примере мы не добавляли curl в собранный контейнер, поэтому мы должны сначала прокинуть порт 8081 пода service-back-sample:
C:\Windows\System32>kubectl port-forward service-back-0.01-57f7f4df4-ghnjn 8081 -n myproject
Forwarding from 127.0.0.1:8081 -> 8081
Forwarding from [::1]:8081 -> 8081
И дальше вызвать конечную точку для метрик Прометеуса: http://localhost:8081/actuator/prometheus
Кроме, запрограммированных нами метрик ( OPERATION_CODE, OPERATION_TIME и др), будут выданы системные метрики фиксируемые библиотеками Spring Boot (jvm_memory_used_bytes, jvm_classes_loaded_classes итд), на основании которых, мы потом создадим дашборд для мониторинга ресурсов приложения, но сейчас нас интересуют прикладные метрики:
operation_code_total{business_process="service-back-main",code="OK",} 2763.0
operation_code_total{business_process="service-back-main",code="VALIDATION_ERROR",} 286.0
Как мы видим, счетчик operation_code зафиксировал 2 значения — 2763 раза операция поиска завершилась успешно (тэг code=OK) и в 286 случаях мы получили VALIDATION_ERROR (мы специально настроили генератор нагрузки так, чтобы в 10% случаях он формировал некорректные запросы). Обратите внимание на название метрики. К тому имени метрики, которое мы программно формируем в приложении, добавляется суффикс _total. Дело в том, что одна откидываемая метрика, фактически, фиксирует значение в нескольких разрезах. Для самой простой метрики — Counter, это только один показатель — общее количество (total). Для остальных видов метрик таких показателей больше и для каждого добавляется соответствующий суффикс.
operation_time_seconds_max{business_process="service-back-main",} 0.019287026
# HELP operation_time_seconds
# TYPE operation_time_seconds histogram
operation_time_seconds{business_process="service-back-main",quantile="0.5",} 0.0
operation_time_seconds{business_process="service-back-main",quantile="0.8",} 0.0
operation_time_seconds{business_process="service-back-main",quantile="0.95",} 0.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.001",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.002",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.003",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.004",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.005",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.006",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.007",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.008",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.009",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.01",} 285.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.02",} 3032.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.03",} 3035.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.04",} 3035.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.05",} 3035.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.06",} 3035.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.07",} 3035.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.08",} 3037.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.09",} 3042.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.1",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.125",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.15",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.175",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.2",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.225",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.25",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.275",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.3",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.35",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.4",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.45",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.5",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.6",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.7",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.8",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="0.9",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="1.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="2.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="3.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="4.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="5.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="6.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="7.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="8.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="9.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="10.0",} 3049.0
operation_time_seconds_bucket{business_process="service-back-main",le="+Inf",} 3049.0
operation_time_seconds_count{business_process="service-back-main",} 3049.0
operation_time_seconds_sum{business_process="service-back-main",} 41.811121123
Метрика времени — это гистограмма. Подробнее о ней и ее настройке можно прочитать тут. Метрика времени operation_time фиксирует:
- Общее число регистраций метрики operation_time_seconds_count. Оно равно общему числу вызовов метода поиска
- Суммарное время поиска за все вызовы — operation_time_seconds_sum
- Бакеты для последующего вычисления перцентилей и построения графиков гистограмм. В показателе operation_time_seconds_bucket присутствует автоматически добавляемый тэг le. Он содержит некоторое число (из набора преднастроенных), а значение показателя указывает какое количество раз значение метрики не превысило это число
- В operation_time_seconds фиксируются перцентили уже вычисленные API Micrometer. В большинстве случаев, нужно отбрасывать что-то одно — или бакеты или перцентили. Бакеты позволяют вычислять перцентили на уровне Prometheus, увеличивая нагрузку на него, а перцентили напрямую вычисляются в клиентском приложении.
Теперь давайте убедимся, что отброшенные нашим микросервисом метрики были успешно экспортированы в Prometheus. Для этого прокинем порт 9090, на котором он работает по-умолчанию:
kubectl port-forward pods/prometheus-k8s-0 9090 -n monitoring
И обратимся к URL: http://localhost:9090
В верхней строке ввода начинаем набирать первые символы имени метрики и сразу видим показатели нашего микросервиса:
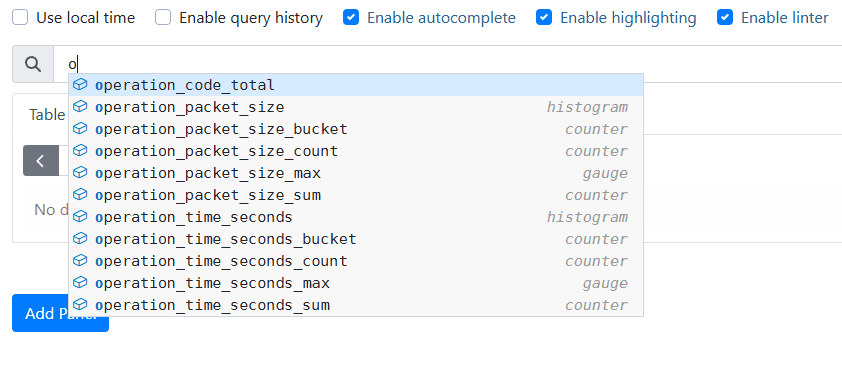
Выберем operation_code_total и увидим те же 2 значения, которые выдавал наш микросервис, но к метрике Prometheus добавил дополнительные тэги, в частности, имя нэймспейса, пода и контейнера. Информация из этих тэгов пригодится нам в Grafana для фильтрации дашбордов.
Нужно отметить, что если мы хотим мониторить только определенные нэймспейсы и приложения, то в настройках манифеста Prometheus мы можем в полях serviceMonitorNamespaceSelector и serviceMonitorSelector указать метки, которые должны присутствовать в нэймспейсах и объектах ServiceMonitor, метрики которых нас интересуют.
Например:
serviceMonitorNamespaceSelector:
matchLabels:
serviceMonitor: prometheus
serviceMonitorSelector:
matchLabels:
serviceMonitor: prometheus
Далее, к интересующим нас нэймспейсам надо добавить метку prometheus:
kubectl patch ns myproject --patch "{\"metadata\":{\"labels\":{\"serviceMonitor\":\"prometheus\"}}}"
А в объектах serviceMonitor будем указывать:
metadata:
labels:
serviceMonitor: prometheus
Если мы таким образом ограничим набор сервисов для мониторинга, то не будем видеть лишней информации в фильтрах Grafana, основанных на тэгах, содержащих нэймспейс и сервис (об этом ниже)
Вернемся к метрикам в Prometheus. Мы можем не только просматривать метрики, но и задавать выражения, использующие встроенные функции Prometheus и правила Prometheus, которые прописываются в конфигмапе prometheus-rules.yaml и являются выражениями, составленными из других выражений и встроенных функций.
Например, в контексте метрики operation_code нас может интересовать график по количеству различных кодов завершения операций в секунду. Для этого можно составить следующее выражение:
sum by (business_process, code) (rate(operation_code_total{service="service-back"}[600s]))
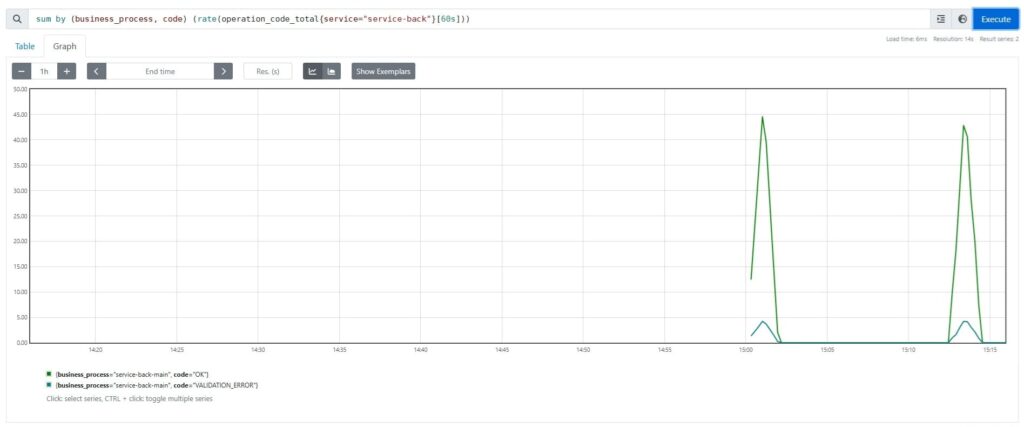
С помощью функции rate мы вычисляем частоту отброса метрики operation_code за последние 10 минут, агрегируя результаты в разрезе бизнес процесса и кода завершения.
Настраиваем дашборды в Grafana
Чтобы зайти в интерфесе Grafana нужно прокинуть порт 3000 для соответствующего сервиса:
kubectl --namespace monitoring port-forward svc/grafana 3000
Далее заходим на http://localhost:3000 и вводим имя/пароль admin/admin.
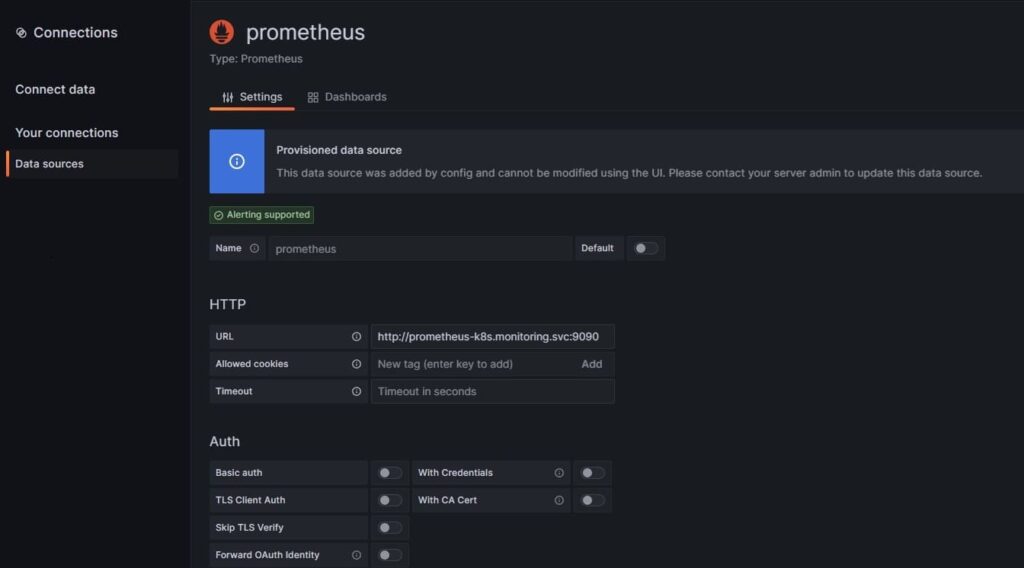
Если Grafana была установлена в составе kube-prometheus-stack, то в ней уже настроен источник данных, который “смотрит” на один из экземпляров Prometheus:
Перед тем как настраивать дашборд нам необходимо определиться с фильтрами. Очевидно, что нам надо иметь возможность фильтровать данные на графиках по имени сервиса, желательно также иметь возможность выбирать конкретный под сервиса, а также указывать бизнес-процесс, к которому относятся метрики. Выпадающие списки для этих фильтров настраиваются в пункте Settings/Variables, а данные берутся из значений тэгов метрик (значения запрашиваются из тегов всех метрик или метрик с определенным именем). Для этого используется функция label_values:
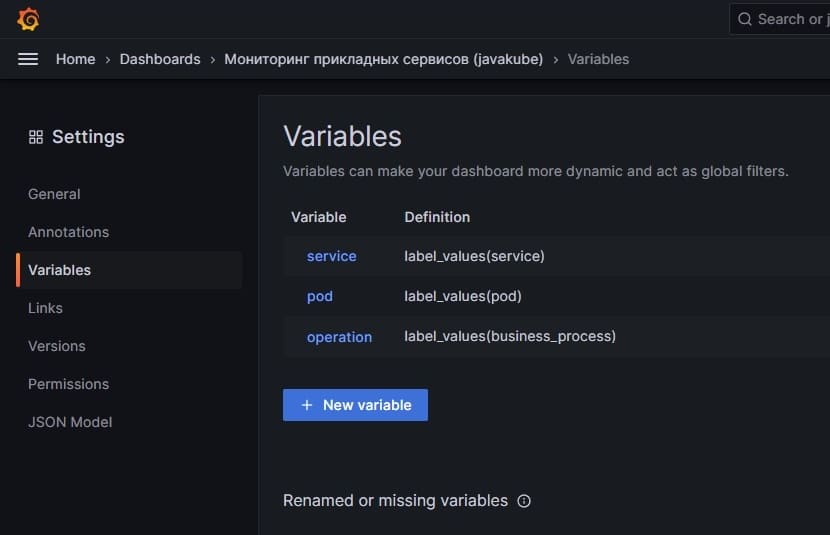
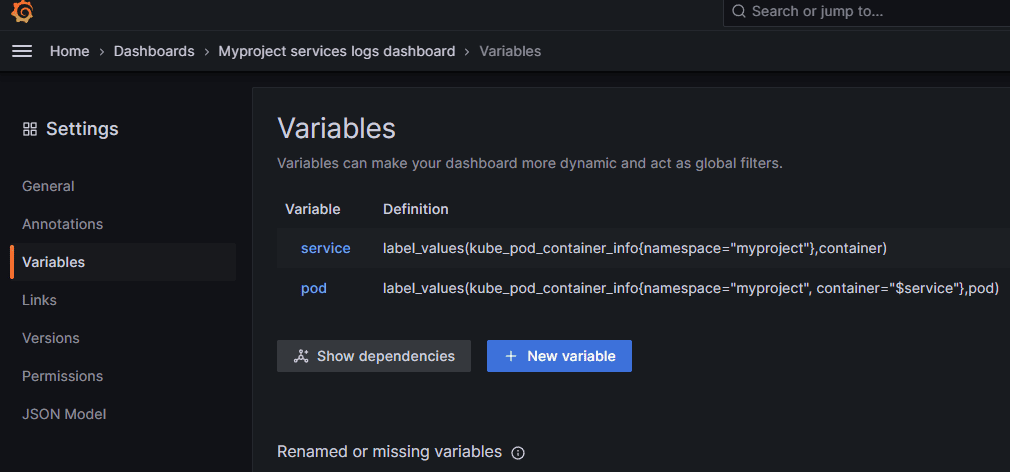
На представленном скрине показан самый простой вариант, когда в выпадающие списки фильтров попадают значения тэгов servive, pod и business_process из всех метрик, собираемых Kubernetes. При этом списки никак не связаны между собой. Другой, более правильный подход, для выбора пода и сервиса — использовать значения тэгов какой-то системной метрики, например, kube_pod_container_info. Тогда для переменной service можно взять значение тэга container, ограничив значение тэга namespace пространством где мы размещаем прикладные сервисы, а для значения тэга под взять список только из метрики kube_pod_container, у которой в тэге container, выбранное значение:
Запрос количества различных кодов завершения операций в секунду выглядит похожим на соответствующий запрос, который мы делали через интерфейс Prometheus, но с двумя отличиями — мы указываем в запросе через переменные $service, $pod, $operation значения, выбранные в соответствующих фильтрах (можно настроить поиск по всем или по нескольким значениям фильтра) и используем встроенную переменную $__rate_interval, которая соответствует выбранному графаной оптимальному интервалу, за который вычисляются значения функции rate.
sum by (business_process, code) (rate(operation_code_total{service=~"$service", pod=~"$pod", business_process=~"$operation"}[$__rate_interval]))
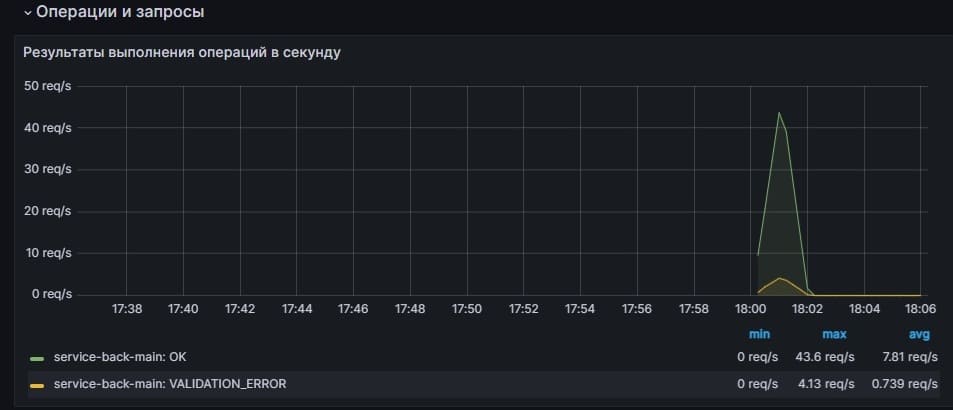
Посмотреть общее количество кодов ответов в разрезе бизнес-процесса и кода можно следующим запросом:
sum(increase(operation_code_total{service=~"$service", pod=~"$pod", business_process=~"$operation"}[$__range])) by (business_process, code)
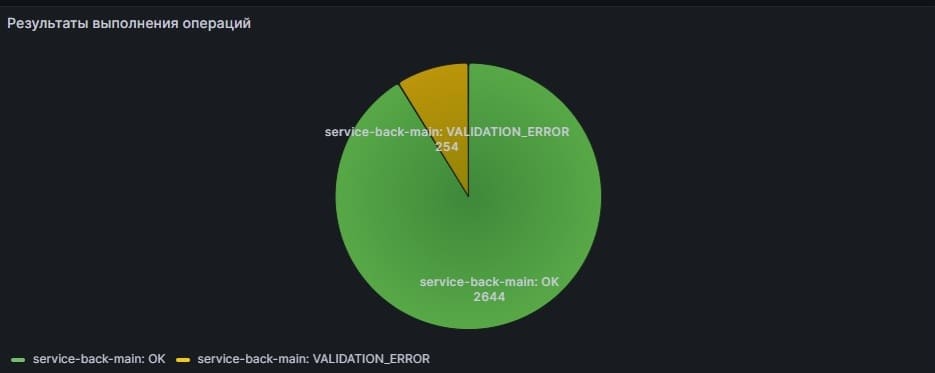
Обратите внимание на функцию increase. Она, в отличие от функции delta, не просто берет разницу значений счетчика, а учитывает, что счетчик мог быть сброшен, если контейнер в поде перезагрузился. Например, если есть следующий ряд значений счетчика:
t0: 5
t1: 11
t2: 28
t3: 4 (после перезагрузки контейнера)
t4: 40
то delta будет равна 40 — 5 = 35, а increase (28-5)+40 = 63
Переменная $__range соответствует выбранному временному диапазону в правом верхнем углу панели мониторинга
Если мы хотим увидеть график по 95-перцентилю времени выполнения операций, то можно сформировать следующий запрос:
histogram_quantile(0.95, sum(rate(operation_time_seconds_bucket{service=~"$service", pod=~"$pod", business_process=~"$operation"}[$__rate_interval])) by (le, business_process))
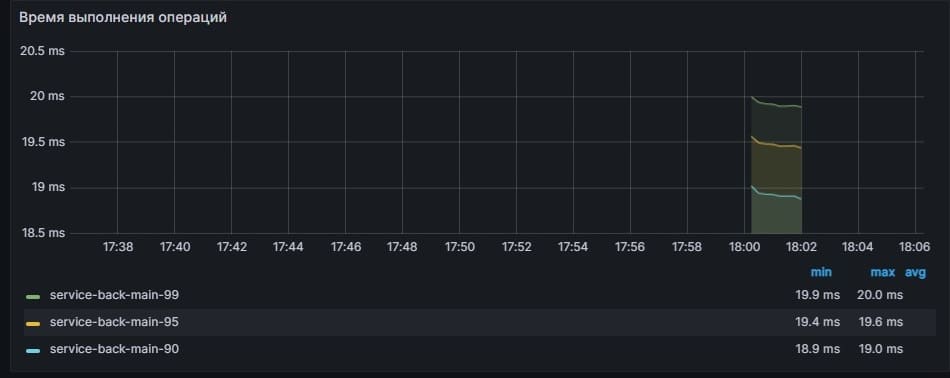
Мы привели в качестве примеров три варианта типовых запросов — скорость изменения значения, общее количество за период и перцентиль по метрике. Есть еще один, самый простой вариант, это график какого-то ресурса (например, памяти, утилилизации CPU итд). В этом случае, в качестве запроса в Grafana можно будет указывать просто имя метрики и параметры для значений тэгов. Например:
jvm_memory_used_bytes{service=~"$service", pod=~"$pod"}
На втором уроке нашего бесплатного курса вы можете получить более подробную информацию по настройке мониторинга, полный код примера откидывания метрик прикладным сервисом и скачать настроенный дашборд для Grafana.
Также рекомендуем прочитать статью о мониторинге кластера Kubernetes
